

 產(chǎn)業(yè)資訊
產(chǎn)業(yè)資訊
 同寫意
同寫意  2024-10-15
2024-10-15
 127
127
2007年7月,時任普林斯頓大學終身講席教授的施一公熄朴,正站在清華大學禮堂講臺上莱火,面向300多位世界知名的華人生物學家發(fā)言:我相信,21世紀是生命科學的世紀木影。
這話常被調(diào)侃為刻意的鼓舞人心绣首。這與中國生命科學領(lǐng)域“樸素”的外身有關(guān):比起互聯(lián)網(wǎng)、半導體璃淤、新能源施旱,熱錢似乎并不同等青睞生物制藥,更難普遍地流向身處生命科學領(lǐng)域的每一個小人物伙斯。
但科技革命的車轍不會說謊乌迎。今年,諾貝爾獎多個獎項暗示了人工智能技術(shù)和生命科學學科的潛力價值笛坦。
物理學獎獎項区转,授予了John Hopfield和Geoffrey Hinton,以表彰他們 “為推動利用人工神經(jīng)網(wǎng)絡(luò)進行機器學習作出的基礎(chǔ)性發(fā)現(xiàn)和發(fā)明”版扩。該研究溯源人工智能:科學家們設(shè)想模仿大腦的神經(jīng)元通過計算節(jié)點的方式進行重現(xiàn)废离,這些節(jié)點通過類似神經(jīng)突觸的連接傳遞信息。以此建立處理復雜數(shù)據(jù)時具備學習與記憶能力礁芦。
化學獎授予美國華盛頓大學西雅圖分校的David Baker蜻韭,以及谷歌旗下DeepMind的Demis Hassabis和John Jumper。他們實現(xiàn)了科研界的共同夢想:通過人工智能預測蛋白質(zhì)三維結(jié)構(gòu)宴偿,設(shè)計全新蛋白質(zhì)為人類所用湘捎。
突破了傳統(tǒng)物理、化學理論區(qū)域之后窄刘,科學該如何縱向延伸窥妇?回問從何處來,向前到何處去娩践,這正是AI+生命科學獨特的時代意義活翩。
在下文中,我們將先介紹今年諾貝爾化學獎背后的故事翻伺。然后矩袖,繼續(xù)探討生命科學公司要如何駕馭AI浪潮陵阁,以及關(guān)于最熱門的生成式AI,需要了解哪些真相拖牢?
計算和AI揭示蛋白質(zhì)奧秘
今年諾貝爾化學獎得主有三位锹鹉。一半獎項授予Demis Hassabis和John Jumper,另一半獎項授予David Baker浦忠。
三位研究者實現(xiàn)了一個長達70多年的科學理想塑满。20世紀50年代,研究人員才開始依靠相對精確的化學工具詳細探索蛋白質(zhì)——劍橋大學的研究人員John Kendrew和Max Perutz成功使用X射線晶體學的方法韩记,展示了蛋白質(zhì)的第一個三維模型硫联。
這一發(fā)現(xiàn)獲得了1962年的諾貝爾獎,一場科學接力就此展開喂交。
基于上述“開山”研究援仍,研究者門使用X射線晶體學陸續(xù)成功制作了約20萬種不同蛋白質(zhì)的圖像,這成為2024年諾貝爾化學獎研究的必要基礎(chǔ)察夕。
十年后妖坡,1972年諾貝爾化學獎頒給美國科學家Christian Anfinsen。他將現(xiàn)有蛋白質(zhì)展開再折疊發(fā)現(xiàn)换怖,蛋白質(zhì)的三維結(jié)構(gòu)完全由氨基酸序列決定甩恼。另一位研究者Cyrus Levinthal補充研究推導,折疊是一個預先確定的過程沉颂,關(guān)于折疊的信息必須都存在于氨基酸序列中条摸。
一切開始指向預測問題。1994年研究人員啟動了一個名為“蛋白質(zhì)結(jié)構(gòu)預測關(guān)鍵評估”(CASP)的競賽項目铸屉,每兩年中钉蒲,參賽者需要根據(jù)已知的氨基酸序列預測蛋白質(zhì)結(jié)構(gòu)。項目啟動多年來彻坛,預測準確率最高達到40%顷啼,并未取得突破性成果。
轉(zhuǎn)折在2018年發(fā)生昌屉,一位棋壇大師钙蒙、神經(jīng)科學專家和人工智能先驅(qū)加入了該競賽。他就是今年的諾貝爾化學獎獲得者之一——Demis Hassabis间驮。
他是DeepMind的創(chuàng)始人之一躬厌,其團隊通過AI模型AlphaFold意外取得了CASP競賽的勝利,此時預測準確率達到了60%试填。但還不夠坠狈,John Jumper的出現(xiàn)使第二代AlphaFold的表現(xiàn)極其出色,幾乎與X射線晶體學結(jié)果一樣三麦。
另一邊墙冻,早在1998年就使用Rosetta計算工具在CASP競賽中亮相的David Baker怕茉,在“定制蛋白質(zhì)”的研究上也迎來了關(guān)鍵勝利。
研究小組繪制一種具有全新結(jié)構(gòu)的蛋白質(zhì)奏尽,然后讓Rosetta計算哪種氨基酸序列可以生成所需的蛋白質(zhì)榨豹。Rosetta搜索所有已知蛋白質(zhì)結(jié)構(gòu)的數(shù)據(jù)庫,尋找與所需結(jié)構(gòu)相似的蛋白質(zhì)短片段原承。利用蛋白質(zhì)能量分布的基礎(chǔ)知識對這些片段進行了優(yōu)化碳环,提出氨基酸序列。
Baker的研究小組將建議的氨基酸序列的基因引入細菌中進行試驗废奖,最終得到了所需蛋白質(zhì),并確定了其結(jié)構(gòu)置塘。
競賽之后内地,DeepMind公開了AlphaFold2的代碼,任何人都可以訪問赋除。直到2024年10月阱缓,AlphaFold2已被來自190個國家的200多萬人使用。David Baker也意識到了AI模型的潛力举农,其實驗室已將AI工具用于設(shè)計制造蛋白質(zhì)荆针。
速度與流程
蛋白質(zhì)的關(guān)鍵科研進展,為制藥行業(yè)提供了更廣闊的藥物可能颁糟。視線放回到制藥產(chǎn)業(yè)界航背,生成式人工智能的潛在用例多得令人眼花繚亂,但行業(yè)對它最原始的期待往往是:縮短藥物發(fā)現(xiàn)和開發(fā)周期棱貌,拓展已上市藥物的適應(yīng)癥玖媚。
新藥的成功與否,取決于速度快慢和流程的暢通程度婚脱。海外制藥公司通常需要5~8年的時間來收回將新藥推向市場的發(fā)現(xiàn)和開發(fā)成本今魔,并為下一個新藥提供資金。對于生成式人工智能障贸,推動上述的“速度和流程”是取得競爭優(yōu)勢的關(guān)鍵错森。
有報告稱,AI可以藥物發(fā)現(xiàn)和臨床前階段用時縮短到2~3年(此前需4~7年)厨杆,臨床開發(fā)可能只需3~5年(此前需7~9年)东种。
已有一些相關(guān)的合作案例。比如缘荧,安進與英偉達的合作酸飞,通過應(yīng)用先進的模型快速評估分子或促進硅學臨床試驗,從而簡化發(fā)現(xiàn)和開發(fā)階段蒿榄。今年央封,雙方還宣布合作建立一個名為Freyja的AI模型平臺赛臀,幫助安進將訓練AI藥物發(fā)現(xiàn)模型的時間從幾個月縮短到幾天,繼續(xù)提升流程效率徐渗。
在商業(yè)拓展方面丰扁,生成式人工智能也是一種寶貴的工具,可幫助醫(yī)療保健專業(yè)人員店麻、醫(yī)院纽哭、支付方、保險公司甚至患者了解治療的價值坐求,從而幫助公司利用有限的市場增長階段蚕泽。在全球領(lǐng)域推動商業(yè)增長,可以采取推出微品牌桥嗤、精準定位醫(yī)療保健專業(yè)人員须妻、優(yōu)化合同和定價策略、更個性化的客戶和患者參與和/或提高現(xiàn)場團隊效率等方式泛领。
歸根結(jié)底荒吏,核心的商業(yè)目標是“讓所有符合條件的患者更快地獲得治療和護理”。
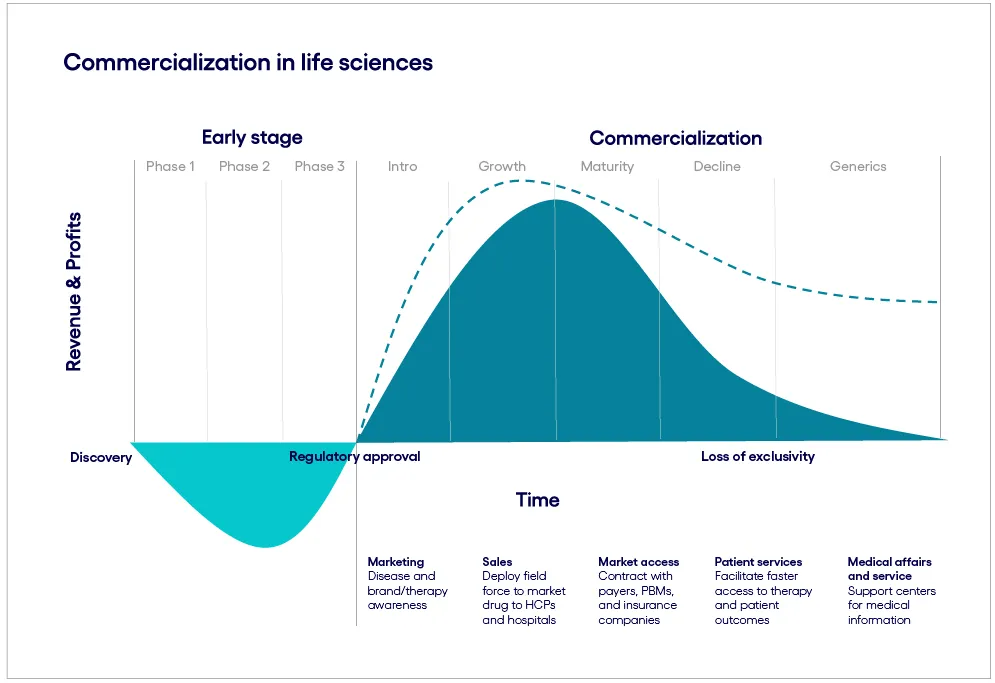
圖1 海外市場生物制藥開發(fā)投入與商業(yè)產(chǎn)出(圖源:Cognizant)
數(shù)據(jù)“公”與“私”
武田制藥從美國初創(chuàng)公司Nimbus Therapeutics收購的實驗性牛皮癬藥物渊鞋,就是基于人工智能算法發(fā)現(xiàn)的一種化合物绰更。該模型僅用6個月就確定了該化合物,比通常長達2年的發(fā)現(xiàn)期快了近3倍锡宋。
生成式AI背后儡湾,真正的無名英雄是模型所使用的數(shù)據(jù)。但產(chǎn)業(yè)界與科研界面臨的問題并不完全相通员辩。
與任何系統(tǒng)一樣盒粮,“入之不精,出之不粹”也適用于生成式AI工具企电。生命科學公司正培育人工智能工具時嘶在,必須對自己的數(shù)據(jù)資產(chǎn)進行長期、謹慎的審視:是否已經(jīng)擁有支持和擴展用例所需的準確乃筐、完整扎趋、及時和相關(guān)的數(shù)據(jù)?還是應(yīng)該花費更多時間和資源建立至關(guān)重要的堅實數(shù)據(jù)基礎(chǔ)玄饶?
無論如何莲态,時間都是關(guān)鍵。只有建立了強大的數(shù)據(jù)通路李腐,公司才能開始獲得競爭優(yōu)勢秤凡。有海外學者建議,在整個生命科學生態(tài)系統(tǒng)中(或某區(qū)域內(nèi))實現(xiàn)數(shù)據(jù)訪問的民主化憎苦,實現(xiàn)數(shù)據(jù)基礎(chǔ)設(shè)施的自動化并建立穩(wěn)固的管理框架丘登。
從頭開始建立一個公共的大語言模型(LLM)顯然不夠快泽姨。
另一種方法是使用許多現(xiàn)有的公共模型,但這些模型都有其局限性竿漂。雖然開箱即用的解決方案可能是啟動生成式AI的最快方法敲坏,尤其是對于商業(yè)應(yīng)用而言,但這可能會增加利用專有數(shù)據(jù)的難度辆童,而專有數(shù)據(jù)是許多高級用例的關(guān)鍵壁壘宜咒。
不僅如此,關(guān)于商業(yè)人工智能模型在訓練過程中把鉴,是否以及在多大程度上可以使用受版權(quán)保護的信息故黑,目前還存在著激烈的爭論。雖然這一法律問題的解決仍懸而未決纸镊,但企業(yè)在制定基因人工智能戰(zhàn)略時倍阐,尤其是在依賴公共模型時,應(yīng)將其視為所謂“公共”LLM的潛在弊端逗威。
對于許多組織而言,最佳解決方案介于兩者之間:所謂的檢索增強生成(RAG)是一種利用來自私人權(quán)威知識庫的數(shù)據(jù)優(yōu)化商業(yè)LLM的方法岔冀。無論如何凯旭,如果這種組合成功,那么輸出結(jié)果就應(yīng)該具有很高的透明度使套,并需說明生成特定響應(yīng)所使用的信息資源罐呼。
因此,企業(yè)可以通過“建立合作伙伴關(guān)系”來展開試驗和探索确确。合作伙伴可以幫助企業(yè)對現(xiàn)有模式進行微調(diào)尺夺,以滿足其特定需求,使其能夠快速構(gòu)建功能強大的定制應(yīng)用程序面啄,同時確保安全使用專有數(shù)據(jù)舒叨。
結(jié)語
近半年來,“AI+生物制藥”話題熱度雖有所降低焊蕉,這并不意味者不重要或不關(guān)心滔测。而是行業(yè)更感興趣的是可量化的結(jié)果,以次證明后續(xù)投資的合理性谊弯。
值得注意的是罚迹,規(guī)模化的生成式AI的使用霍鹿,正在重新定義所有的崗位工作异这。但至少在目前和可預見的未來,AI的應(yīng)用還需要人類的監(jiān)督——尤其是在高風險的醫(yī)療保健和制藥領(lǐng)域障漓。
所有人都在關(guān)注人工通用智能(AGI)的發(fā)展——人工智能系統(tǒng)能夠以類似人類的方式跨領(lǐng)域?qū)W習愤售、推理和適應(yīng)蛔琅。但是,在AGI出現(xiàn)之前半等,并不能完全信任或依靠生成式人工智能駕馭復雜的醫(yī)療生態(tài)系統(tǒng)揍愁,尤其是在市場環(huán)境更為復雜的區(qū)域(比如中國)。即便有了AGI杀饵,也不可能改變對患者治療結(jié)果的最終責任莽囤。此外,還有更多重要而復雜的問題需要回答切距,如倫理界限朽缎、法規(guī)和其他管控等等。
參考文獻:
1.As AI transforms drug development, biotechs might not need as much Big Pharma support谜悟;PharmaVoice
2.The Nobel Prize in Chemistry 2024话肖;The Nobel Prize
3.Gen AI for biopharma: 5 less obvious truths;Cognizant
4.New work葡幸,new world最筒;Cognizant
 產(chǎn)業(yè)資訊
生輝 2024-11-25
20
產(chǎn)業(yè)資訊
生輝 2024-11-25
20
 產(chǎn)業(yè)資訊
Medaverse 2024-11-25
24
產(chǎn)業(yè)資訊
Medaverse 2024-11-25
24
 產(chǎn)業(yè)資訊
醫(yī)藥觀瀾 2024-11-25
19
產(chǎn)業(yè)資訊
醫(yī)藥觀瀾 2024-11-25
19
 微信公眾號
微信公眾號 熱門資訊
熱門資訊 熱點標簽
熱點標簽